Notion如何处理2000亿条笔记
Notion技术栈初步分析
Notion use React, TypeScript, Node.js, Postgres, Docker.
I believe the web application is running in Next.js since in browser console you can see some _next tags which is used in Next.js applications
The mobile app uses React native.
架构演进进程
2021-单个Postgres数据库
当用户/文档数量上升后,这显然会出现问题,一旦单个数据库宕机,所有用户都将受到影响(Notion的notes都是在线呈现的,没有离线功能)
Sharding
为了应对上述出现的问题,Notion采用了Sharding,即分片策略
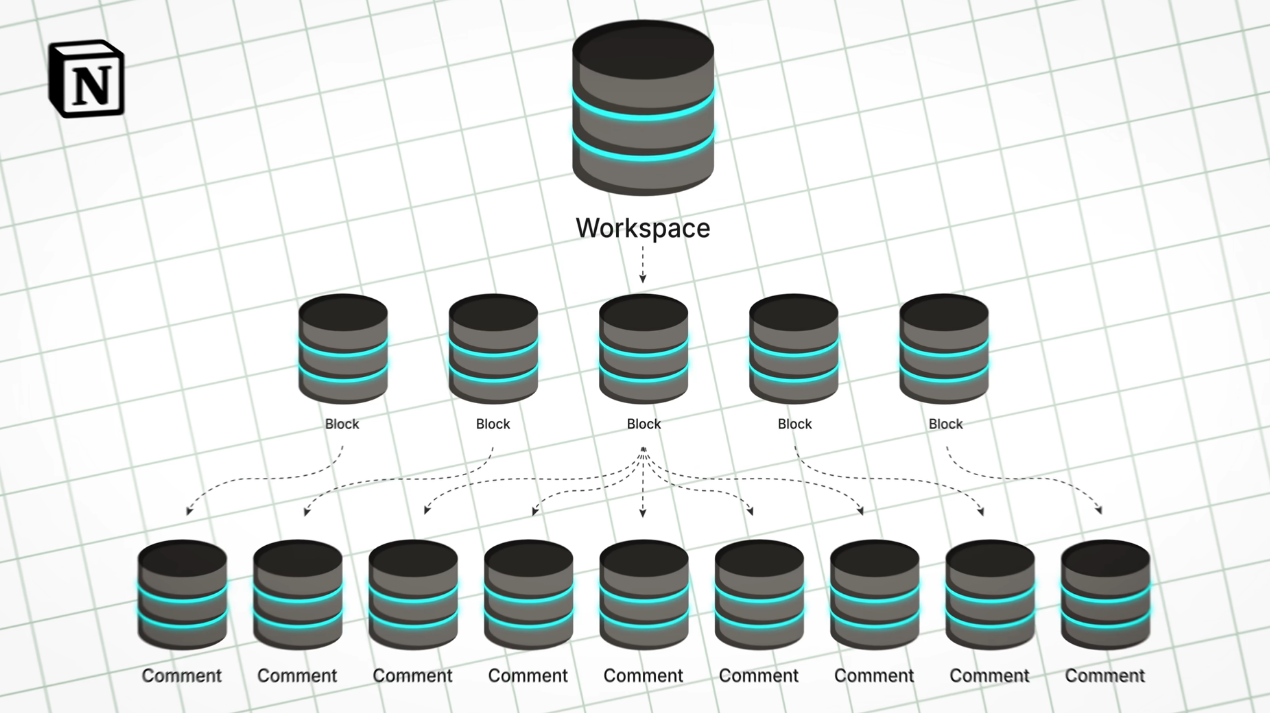
Notion团队将1个数据库拆分为了32个数据库,每个数据库有15分分片
Sharding具体是怎么做的?
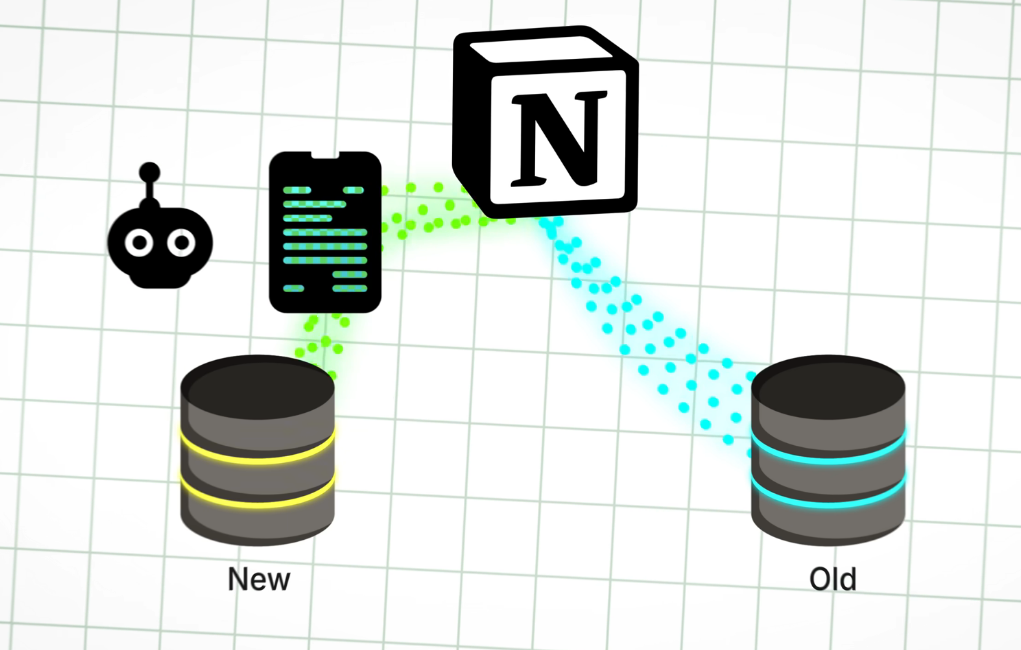
就已知的信息来看,其中一种方式是双重写入(Dual write)
数据库双重写入(Dual Write)是一种在数据库系统中同时向两个或多个数据库实例写入数据的策略,通常用于以下场景:
- 数据迁移:在从旧数据库迁移到新数据库时,通过双重写入确保新旧数据库的数据一致性。
- 高可用性:将数据同时写入主数据库和备用数据库,以提高系统的容错能力。
- 异构数据库同步:在不同类型的数据库(如关系型和NoSQL)之间保持数据一致。
- 分布式系统:在微服务架构中,不同服务可能需要将数据写入各自的数据库,同时保持一致性。
Notion团队利用了96个cpu,在三天的时间里完成了这一过程
数据变更(如插入、更新、删除)通过 Write-Ahead Logging(WAL)记录,为后续的增量数据捕获提供基础。
Data Lake的引入
起初Notion使用Snowflake作为data lake,但data lake并不擅长更新操作(试想一下,在写notion文档时,实时会有很多数据库的Update操作,当用户和文档数量呈指数级别上升时,Snowflake显得效率不足)
Custom Data Lake&System structure
Notion在当时的目标

最终选用的基建
消息队列
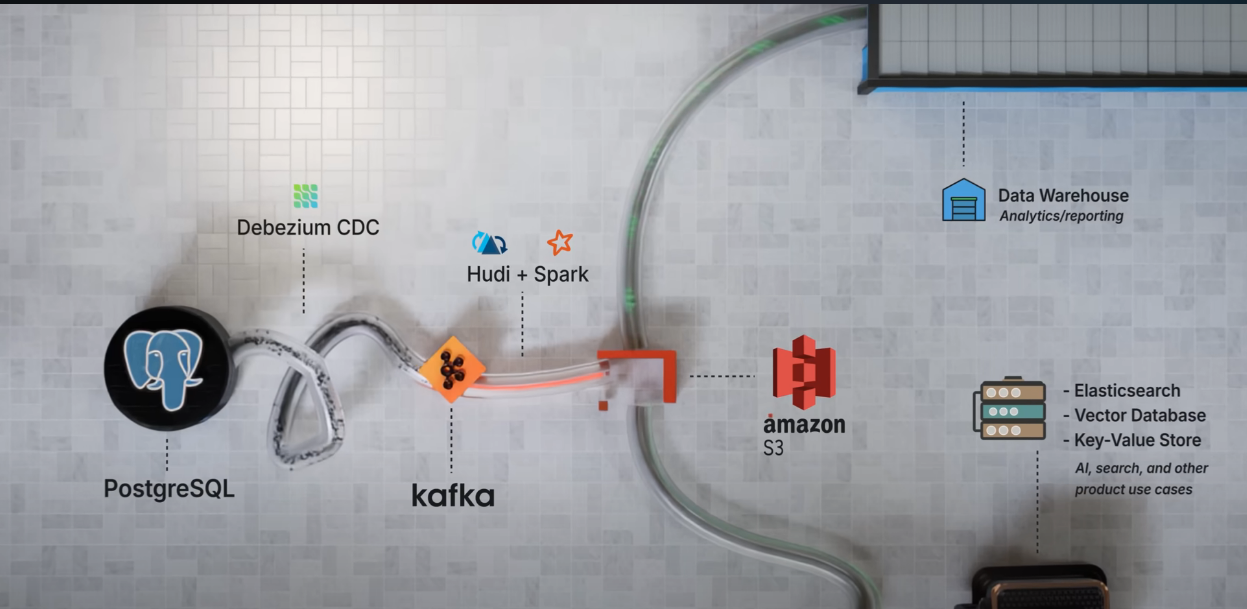
- Kafka 作为分布式消息队列,接收 Debezium 捕获的 PostgreSQL 变更事件,处理高吞吐量的数据流(每秒数十 MB 的行变更)。
- Kafka 主题按表组织,变更数据以事件形式存储,支持高可扩展性和低延迟的数据传输。
- Kafka 确保数据流的高可用性和容错性,同时支持下游消费者(如 Spark)订阅和处理数据。
数据处理与摄取:Apache Spark 和 Apache Hudi
- Spark 处理:
- Spark 作为主要的数据处理引擎,运行在分布式环境中,能够处理数百 TB 的数据。
- 使用 Apache Hudi 的 Deltastreamer(基于 Spark 的摄取工具)从 Kafka 主题消费消息,将数据写入 S3。
- Spark 作业对数据进行清洗、聚合和转换(例如树遍历、去规范化、权限数据构建),生成适用于分析和机器学习的处理后数据。
- Notion 采用 PySpark 处理大部分任务,因其易用性和低学习曲线;对于复杂操作(如树遍历和去规范化),使用 Scala Spark 以提升性能。
- Hudi 优化:
- Hudi 使用 COPY_ON_WRITE 表类型,支持更新密集型工作负载,通过 UPSERT 操作更新数据。
- 数据按 PostgreSQL 的 480 分片方案分区(hoodie.datasource.write.partitionpath.field: db_schema_source_partition),并基于最后更新时间(event_lsn)排序,使用布隆过滤器(bloom filter)作为索引类型,以优化查询性能。
- 大小分片分别处理:小分片数据加载到 Spark 任务容器内存中以加速处理;大分片通过磁盘重排(disk reshuffling)处理,避免内存溢出。
- 多线程和并行处理进一步优化了 480 个分片的处理效率。
数据存储:AWS S3(数据湖)
- S3 作为数据湖的核心存储,保存原始数据和处理后的数据,兼容 Notion 的 AWS 技术栈。
- 数据摄取采用混合策略:
- 增量摄取:通过 Debezium 和 Kafka 捕获实时变更,Hudi Deltastreamer 将变更写入 S3,数据新鲜度保持在几分钟到两小时(对最大表"block table"约为两小时)。
- 偶尔全量快照:通过 AWS RDS 的 export-to-S3 功能生成 PostgreSQL 表的完整快照,用于初始化新表(因全量快照耗时超 10 小时且成本高,仅在必要时使用)。
- 原始数据作为单一事实来源存储在 S3,处理后的数据用于下游系统(如 Snowflake、ElasticSearch、向量数据库等)。
数据流向总结
- PostgreSQL → Debezium:捕获数据库变更,生成事件。
- Debezium → Kafka:将变更事件发布到 Kafka 主题(每表一个主题)。
- Kafka → Spark (Hudi):Spark 通过 Hudi Deltastreamer 消费 Kafka 消息,处理数据并写入 S3。
- S3 → 下游系统:原始和处理后数据存储在 S3,供 Snowflake、向量数据库等下游系统使用,支持分析和 AI 功能。
Second Sharding Implementation
Notion进行了再分片(re-sharding),将物理实例数量从32个增加到96个,同时调整每个实例的逻辑分片数量为5个,保持总逻辑分片数为480个(96 × 5 = 480)。这一更新旨在应对2022年末的性能瓶颈,包括某些分片在高峰期CPU利用率超过90%,接近IOPS上限,以及PgBouncer(连接池)面临连接限制。
调整内容:
- 物理实例数量从32个增加到96个,三倍于之前的规模。
- 每个物理实例的逻辑分片数量从15个减少到5个,确保总逻辑分片数保持480个。
实现方式:
- 使用PostgreSQL逻辑复制(logical replication)进行数据同步,每个现有数据库使用3个发布(publications),每个覆盖5个逻辑分区。
- 通过跳过索引创建等优化,同步时间从最初的3天减少到12小时。
- PgBouncer也被调整,分为4个组,每组处理24个数据库,以替代单一集群的模式,减轻连接压力。
测试与验证:
- 在测试环境中进行"暗读"(dark reads),将结果与主数据库进行比较,并使用1秒暂停确保复制赶上。
切换过程:
- 暂停流量,停止客户端连接。
- 验证复制已赶上。
- 更新PgBouncer到新数据库URL,撤销旧访问权限,并翻转复制。
- 恢复流量。
结果:没有观察到停机时间,没有数据丢失,CPU和IOPS利用率显著下降。