分布式共识算法与Raft
Algorithms are often designed with correctness, efficiency, and/or conciseness as the primary goals. Although these are all worthy goals, we believe that understandability is just as important. None of the other goals can be achieved until developers render the algorithm into a practical implementation, which will inevitably deviate from and expand upon the published form. Unless developers have a deep understanding of the algorithm and can create intuitions about it, it will be difficult for them to retain its desirable properties in their implementation.
分布式共识算法的背景
1.1 如何提高大规模数据的读写性能
(1) 纵向扩展 提升机器性能(如果机器宕机了怎么办?)
(2)横向拓展 设立更多机器,在理想化的网络环境下,可以做到性能上不封顶,还可以在系统安全性方面做到状态数据的容灾备份,更能通过负载均衡减轻单个节点压力。
1.2 分布式的优势和问题
在这里,主要关注的是多节点的横向分布式,而非基于职责内聚性而进行模块划分并通过rpc交互串联整体的纵向分布式。
其优势是明显的,主要是两大点 (1) 数据备份&安全 (2) 负载均衡
但也会带来许多问题: (1) 如何保证不同节点的数据一致性(最终一致性和即时一致性) (2) 如何保证分布式系统的秩序(能正常运行,不会出现脑裂,崩溃,过长等候等问题)
当没有任何故障,失败的时候,分布式系统是一个较为简单的议题,而当故障,失败接踵而至的时候,问题就会变得棘手起来。
1.3 CAP理论
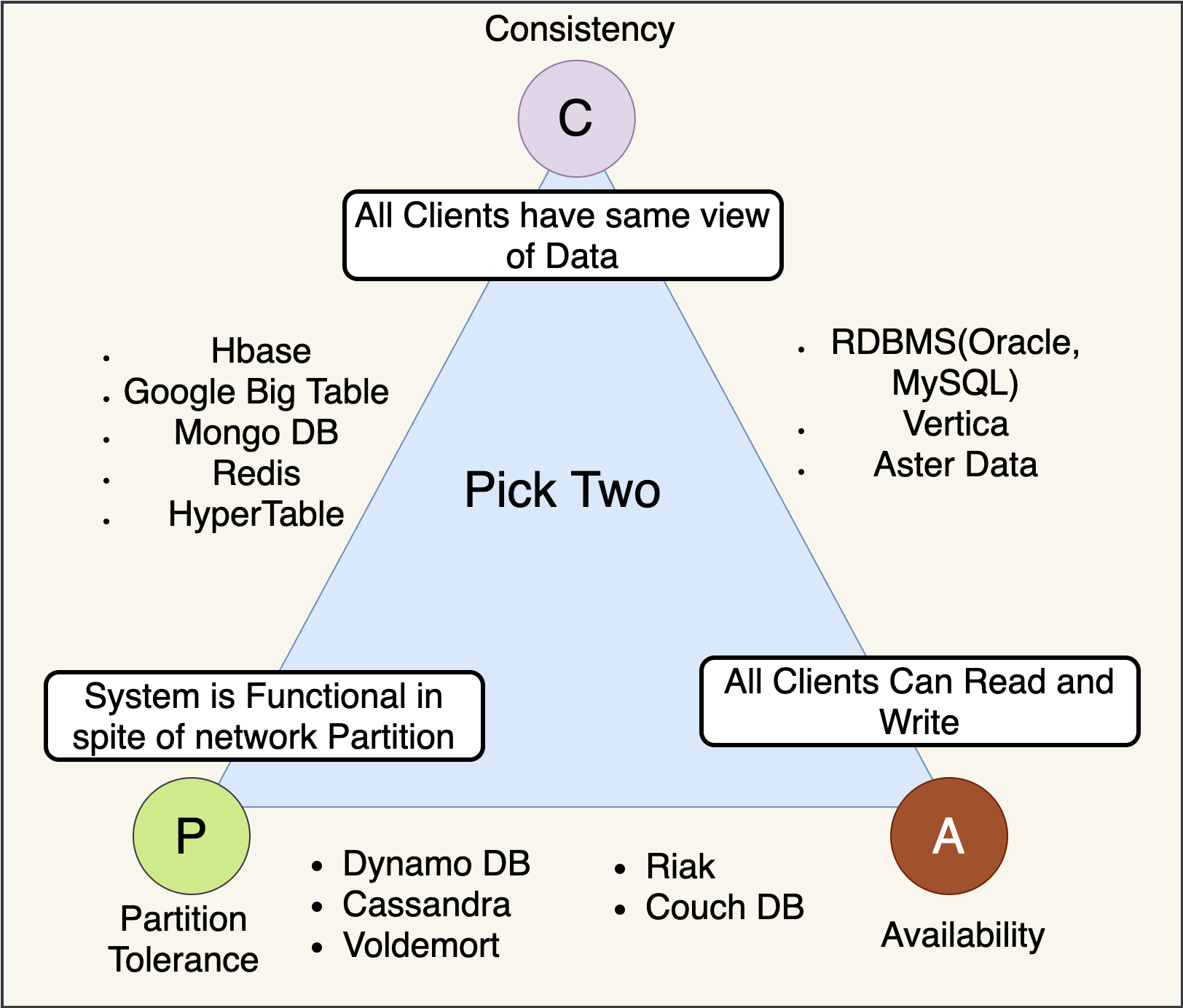
(1) C,即Consistency 一致性
具体而言,对于读操作,要么读到最新,要么读失败,写操作作用于集群像作用于单机一样,具有广义的“原子性”
(2)A,即Availability 可用性
该项站在使用者的角度,强调使用服务的体验,客户端的请求能够得到相应,不发生错误,也尽可能不发生过久的延迟
(3)P,即Partition tolerance 分区容错性
在网络环境不可靠的情况下,整个系统仍然正常运作,少量故障节点不影响整体服务运行
在分布式系统中,一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance)三者无法同时全部满足,最多只能同时实现其中两个。这一定理后来由麻省理工学院的Seth Gilbert和Nancy Lynch在2002年从理论上证明,确立了它的严谨性和权威性。
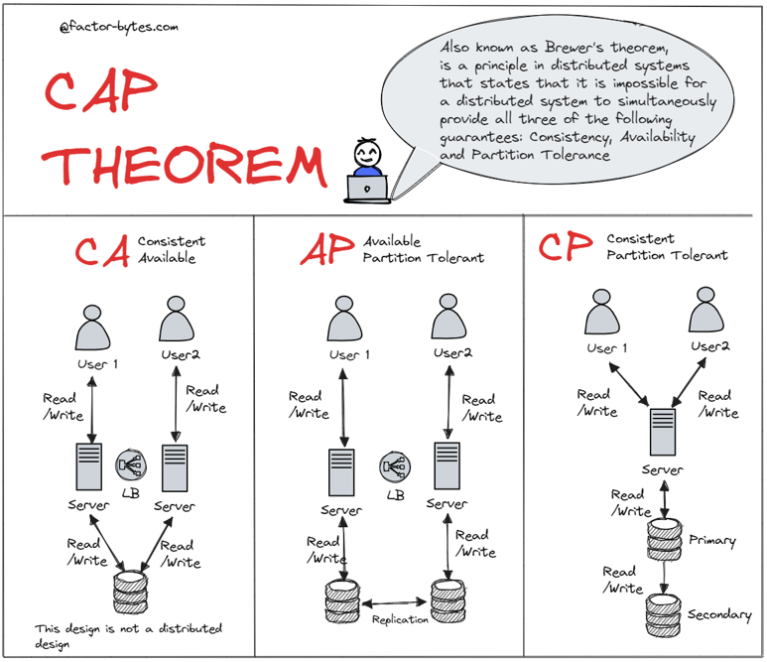
分布式系统中,P是必须得到保证的,不然就违背了分布式的定义
这样,分布式系统主要是两种,CP与AP
CP:牺牲高可用,强调数据一致性
AP:牺牲数据强一致,保证高可用
1.4 C的问题
(1)即时一致性问题(强一致性)
| 典型场景 | 金融、订单、分布式数据库 |
|---|
所有节点数据的绝对一致,要求每次写操作都需要在所有副本间同步确认,只有所有节点都完成更新后,写操作才算完成。
(2)最终一致性问题
| 典型场景 | 社交网络、缓存、新闻推送 |
|---|
系统不保证每次读操作都能获得最新的写入数据,但最终状态会收敛到一致。
1.5 A的问题
串行处理的方式能够保证数据的强一致性,但是会存在哪些问题呢?
(1)倘若集群中某个 follower 出现宕机, master 同步数据时会因为未集齐所有 follower 的响应, 而无法给客户端 ack,这样一个节点的问题就会被放大到导致整个系统不可用;
(2)倘若某个 follower 的网络环境或者本机环境出现问题,它给出同步数据响应的时间出乎意料的长,那么整个系统的响应效率都会被其拖垮,这就是所谓的木桶效应.
1.6 木桶效应
在分布式系统中,强调C则舍弃了A,突出A则违背了C,这样会使得被舍弃方成为了木桶效应中的短板。
但在真实的设计时,很多事情并非非黑即白的,存在一些过渡地段,Raft正是在A和C的过渡地段找到了一块合适位置
1.7 分布式一致性共识算法
分布式一致性共识算法突出其实现目标为数据一致性。
但也同时做到了在尽可能少的牺牲C的基础上,实现较高的A。
Raft就是这样的一个角色:
在一致性C方面,Raft能够保证数据的最终一致性(一些工程优化算法可以使其坐到即时一致!)
在可用性A方面,Raft能够保证的是,当有2F+1及以上的节点时,即使F个节点出现故障,也可以维持系统稳定可靠(但不支持拜占庭错误)
Raft前置
2.1 多数派机制
在分布式系统中,多数派机制指的是:
- 某项操作(如写入、提交、选举)只有在获得超过半数节点同意时,才被认为是有效的。
- 这样可以保证即使部分节点失效或网络分区,系统依然能保持一致性。
为什么需要多数派?
- 防止脑裂(brain split):如果没有多数派约束,不同分区可能各自做出决策,导致数据不一致。
- 保证唯一性:任何两个多数派集合至少有一个节点重叠,这样可以防止不同决策同时生效。
多数派机制大大提升了A的分数(当有节点出现故障时,整个系统正常运行),但在多数派原则下如何维持C是需要考虑的
2.2 一主多从 读写分离
Raft协议中还包括以上两个设定
一主多从:
在任意一个任期内,最多只有一个Leader,Leader总揽全局,处理事务的推进
Follower投出选票决定Leader,并有权力推翻Leader
读写分离:
读操作可以由集群任意节点提供服务
写操作统一由Leader收口处理,并向Follower广播同步,若Follower先收到写请求,也需要转播给Leader进行处理
这种读写分离机制,通过读操作的负载均衡提高了系统整体吞吐量,也通过写操作的统一收口降低了共识算法的复杂度,但也衍生出两个问题
1.即时一致性若无法保证的话,可能会造成stale read
2.leader出了问题的话怎么办?对此Raft有一套易懂,完善的领导选举机制
2.3 状态机 预写日志
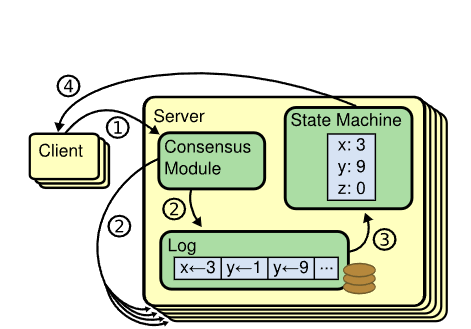
状态机是节点实际存储数据的容器(常见的就是KV Store)
写请求的最后一步是将结果写入状态机,而读请求也需要从状态机获取数据进行响应
预写日志即Write-Ahead Log
在Raft算法中,写请求会先组织成预写日志的形式添加到日志数组中,当一个日志获得多数派的认可后,才能够被提交(commit),将变更应用到状态机中
为什么不直接把写请求应用到节点的状态机中?
两阶段提交,第一阶段是预写日志,第二阶段才是Commit日志,并将其应用到状态机里
- 防止节点故障导致数据丢失
- 当领导者(leader)收到客户端请求时,首先将操作写入本地日志(但还未提交)。
- 只有日志被复制到多数派(quorum)节点后,才算“提交”。
- 如果节点在操作还没写入日志前宕机,这次操作就会丢失,系统可能出现不一致。
- 保证崩溃恢复后的一致性
- 节点重启时,可以通过日志恢复到崩溃前的状态。
- 只有已经写入日志的操作才会被恢复,未写入的不会被错误地执行。
- 实现原子性和顺序性
- 日志条目按顺序编号,所有节点按相同顺序应用操作。
- 这样可以保证所有节点最终状态一致。
2.4 two-phase commit
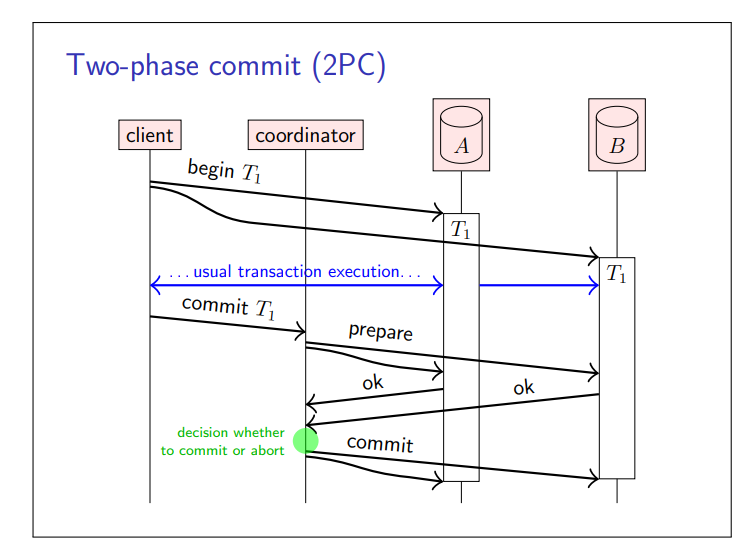
确保多个节点间原子提交的最常见算法是两阶段提交(2PC)协议
在Raft算法中,Leader充当了Coordinator的角色
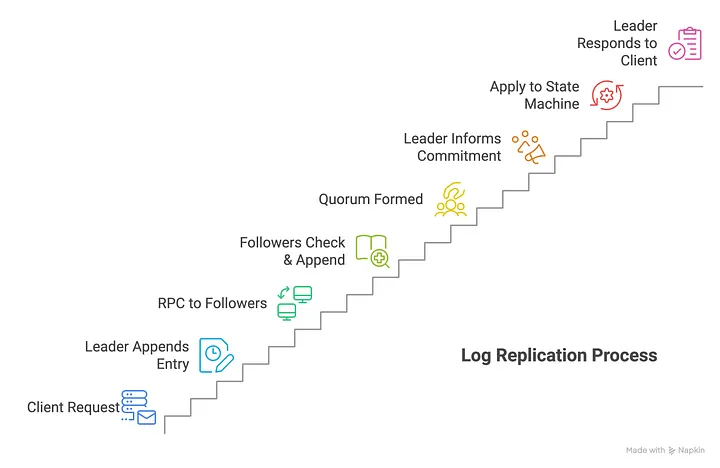
Raft中的两阶段提交可以归纳为以下几个阶段
- leader接收到Client Request
- leader将request包含的写请求,写到本地的log数组里,并propose,将集群中其他节点广播这笔写请求
- 集群中各节点接收到同步请求后,会进行一套检验机制(之后详细叙述)并判断能否执行同步
- 若Quorum Formed,则返回leader 肯定答复,leader将会提交请求,并给予客户端写请求已成功处理的相应
- 其他节点会在之后根据心跳机制了解到Commit动作,也会在自己的预写日志中提交这笔请求
- 被提交的预先日志会在一些特定时间应用到状态机中,实现机制依据系统对一致性的容忍度而定,若只追求最终一致性,则可以选择异步
上面的第二步是提议阶段,第四步是提交阶段,这便是Raft中的二阶段提交。
Raft深入
3.1 领导选举&任期
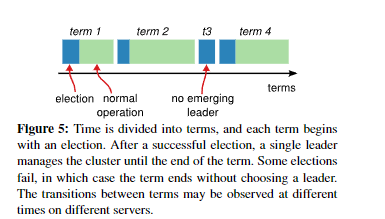
在分布式系统中,Logical Clock是用来衡量事件顺序的抽象计时器,因为分布式系统中机器的物理时钟存在漂移和误差,且我们需要知道事件的先后和因果关系,并区分不同阶段,防止旧消息影响新决策。
在 Raft 中,term 就是 logical clock 的具体实现,节点通过 term 来判断信息的新旧和领导者的合法性。
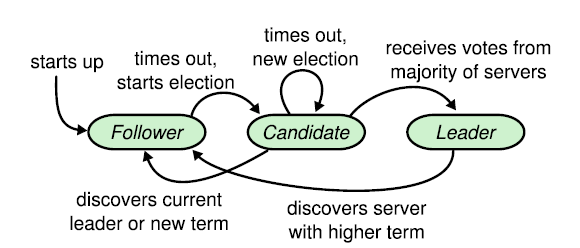
这张图很好地说明了Raft的领导选举机制
节点共有三个角色:Follower,Candidate,Leader
- 刚启动,所有节点都是Follower(或者Leader没了,剩余的都是Follower)
- 发现没有来自Leader的心跳同步包(Leader发送的心跳是跟着AppendEntriesRPC请求一起的,哪怕没有数据也可以发空payload代表这个请求只用于心跳用途),等待任期超时(每个节点的超时时间都是不同的,随机的,意图是这样能有效避免选票分散在多个同时发起选举的候选人身上)
- 某些节点超时了,触发选举,将自己从Follower提升到Candidate,发送投票请求(RequestVote RPC)给所有节点(会携带上任期号term和最新的日志下标lastLogIndex, lastLogTerm)
- 节点收到投票请求,会和本身的当前任期对比,如果自己所处的任期大于对方的,或者自己的日志比对方更多,拒绝投给对方,否则就投票给对方(同节点可能会收到多个投票请求,也是基于这个逻辑来确认投给谁)
- 最终票数多的成为Leader(也有可能票数一样导致没有Leader产生,就会等下一任期到来再选举一波),开始定期发心跳维持自己的地位(某个节点在超时时间内收到Leader的心跳会重启超时等待,直到没收到就会回到Step 2.开启新的选举),此时其他节点全部退回Follower状态
3.2 日志复制


每个节点自身都维持了一个状态机(State)在内存,代表目前的数据情况,只有被确认提交的数据会进到这里,收到但还没确认的不会
日志追加的方式,通过AppendEntriesRPC请求同步给其他的节点,在大多数的节点确认后,会进行提交, 这样能有效确保Leader切换后数据不会丢失(拥有的日志越多的节点约有可能成为下一任Leader)
整体流程如下:
- 收到写数据请求,操作附加到自己的日志中(此时还没提交生效)
- 发送日志给其他节点(发AppendEntriesRPC请求),信息里面会包含一些诸如任期号、LeaderID,日志条目和下标等信息
- Follower节点收到后,检查自己的日志条目情况,如果匹配就追加最新的,不匹配的话拒绝(Leader给的前面的Log的任期不同之类的情况)
- Leader收到超过半数节点的成功响应后,确认已经传播到多数节点了,该日志条目被标记为提交(commited),应用条目到自己的状态机中(下一次AppendEntriesRPC就会告知Follower已经提交到这个位置,Follower也可以跟着提交到这个下标位置的Log)
- Leader响应客户端
在此期间,Step 3.会有个分叉逻辑,就是Leader需要补发Follower缺失的Log, Log下标会往前推直到这个Follower最后的Log位置(此时会借助一些任期号来加快定位到需要补的日志的开头)
3.3 安全性保证
Raft 共识算法通过多种机制确保分布式系统的数据一致性和安全性。下面是核心的安全性设计:
1. 领导者选举安全性
- 每个 term(任期)只能有一个领导者。
- 候选人必须拥有最新的日志才能当选,防止旧领导者或落后节点成为 leader。
2. 日志复制安全性
- 所有写入都先写入 leader 的日志,然后由 leader 复制到多数派(quorum)节点。
- 只有日志条目被多数节点确认后,才算“已提交”,防止部分节点丢失数据。
3. 日志一致性
- 节点在追加日志时,只有前面的日志和 term 都匹配才会接受新日志。
- 如果发现日志冲突,follower 会删除冲突后的所有日志,保持和 leader 一致。
4. 只提交当前 term 的日志
- leader 只会提交在自己任期内被多数派确认的日志,防止旧 leader 的未提交日志被错误提交。
5. 崩溃恢复安全
- 所有节点都通过持久化日志和 term 信息,保证重启后不会丢失已提交的数据
实践过程中的问题/发现
在选举过程中,多个节点可能几乎同时成为候选人,导致频繁竞争和更多的选举超时(选举风暴)。为缓解此问题,Raft 使用随机化选举超时防止选举冲突,保证选举能够顺利完成。
日志复制时,follower 节点的日志可能和 leader 不完全一致,出现旧日志或冲突需要通过回退和覆盖机制解决,确保日志正确且顺序一致,否则会导致状态机差异。为了防止日志无限增大,Raft 需要周期性进行快照和日志压缩,但快照的生成和恢复过程较复杂,需要细致处理。
网络分区与延迟是典型挑战。Raft 在面临网络分区时,会优先保证一致性,导致部分分区中的节点暂时不可用,防止脑裂和错误提交。这是 CAP 定理中一致性与可用性的权衡。
一些边界案例如领导者在未提交日志前崩溃、重复投票、慢节点拖慢进度等也必须考虑。新领导者必须确保包含所有已提交日志,以防止旧日志覆盖已提交数据,保证系统安全。
具体待补充,下篇文章将聚焦CUHK CSCI5600中的Raft Project实践细节与感悟。